

本文档由 AI 自动翻译。如有任何不准确之处,请参考 英文原版。代码节点执行自定义 Python 或 JavaScript 来处理工作流中复杂的数据转换、计算和逻辑。当预设节点无法满足你的特定处理需求时可以使用它。
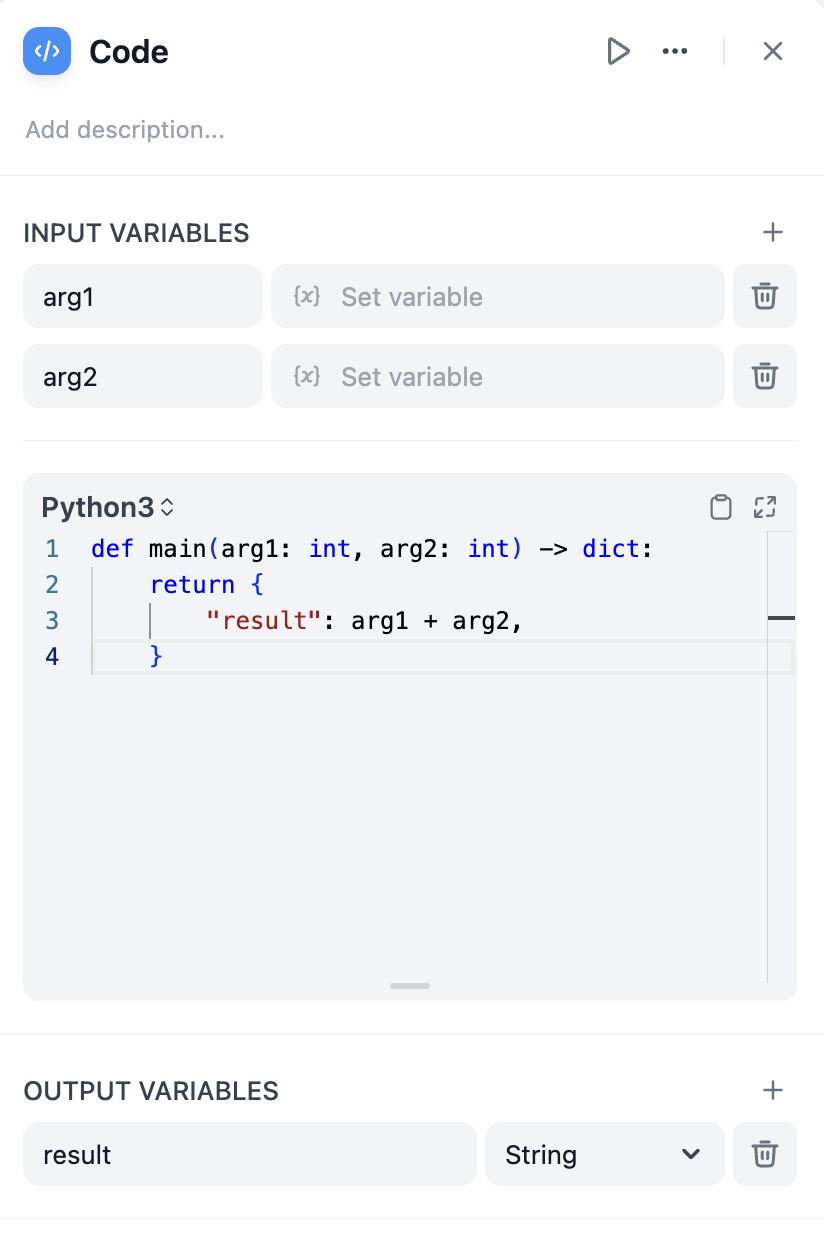
配置
定义 输入变量 以访问工作流中其他节点的数据,然后在代码中引用这些变量。你的函数必须返回一个包含你已声明的 输出变量 的字典。语言支持
根据你的需求和熟悉程度在 Python 和 JavaScript 之间进行选择。两种语言都在安全沙箱中运行,并可访问用于数据处理的常用库。- Python
- JavaScript
Python 包含标准库,如
json、math、datetime 和 re。非常适合数据分析、数学运算和文本处理。错误处理和重试
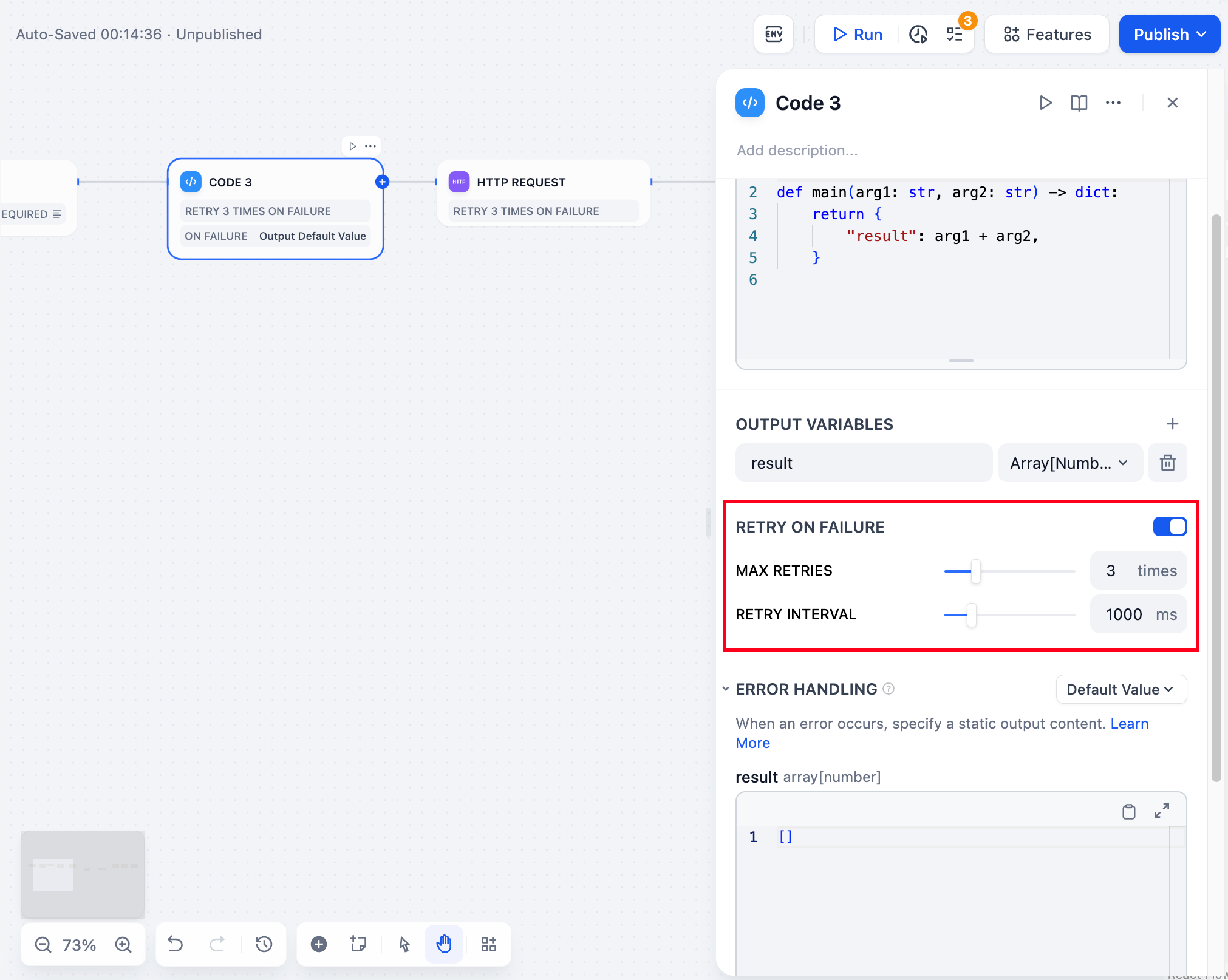
为失败的代码执行配置自动重试行为,并定义代码遇到错误时的回退策略。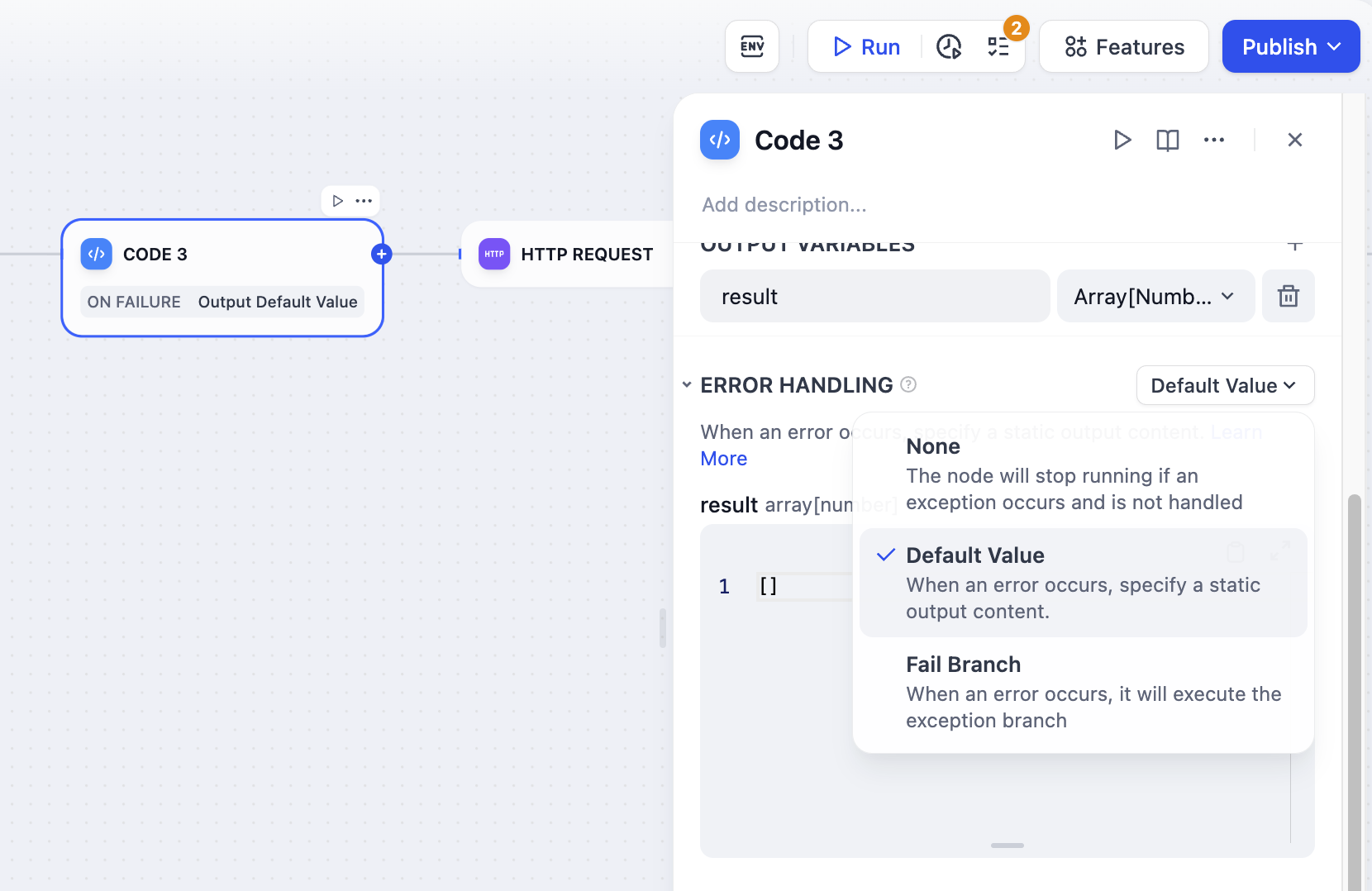
输出限制
在输出传递到下一个节点之前,Dify 会检查其大小是否过大:- 字符串:最多 400,000 个字符。
- 数字:整数最多 19 位,小数最多 20 位。
- 对象和数组:嵌套最多 5 层。